
The purpose
I’ll try running an LLM using an AMD GPU.
I’ll be using DirectML and its sample code.
I’ll modify the code, and please proceed at your own risk.
However, on the following environment, it barely runs (it’s unstable and gives strange answers):
| CPU | AMD Ryzen 7 7735HS |
|---|---|
| Memory | 32GB |
| Storage | external HDD (System Disk is SSD) |
| GPU | AMD Radeon 680M (CPU integrated) |
Setup environment
Create a working folder.
Then, clone the following repository:
Move to your venv Environment (Optional)
If needed, run the following commands in Command Prompt to create and activate your venv environment:
python -mvenv venv
venv\scripts\activate.batMove to working folder
Run the following command to move to the LLM sample code. (The cloned repository is a collection of DirectML sample code, so you’ll need to navigate to the specific working folder to use individual samples.)
cd PyTorch\llmInstall Library
Run the following command to install the necessary libraries.
pip install -r requirements.txt
pip install torch_directml
pip install huggingface_hubModify code
Delete or comment out the following line in app.py:
from huggingface_hub.utils._errors import RepositoryNotFoundErrorEdit as follows or delete the except block:
Before:
except RepositoryNotFoundError as e:after:
except:It seems an error is occurring due to a huggingface_hub version upgrade.
I’m currently able to run it by disabling the problematic parts.
However, it’s possible that the model download error handling isn’t working correctly.
Run
Launch the following command. (The model will be downloaded automatically, so it will take some time the first time you run it.)
python app.pyIf the following is displayed in the command prompt, open the displayed URL in your browser.
Running on local URL: http://127.0.0.1:7860If a screen like the one below appears, you’ve succeeded. (Enter your prompt at the bottom of the screen, and the answer will appear at the top.)
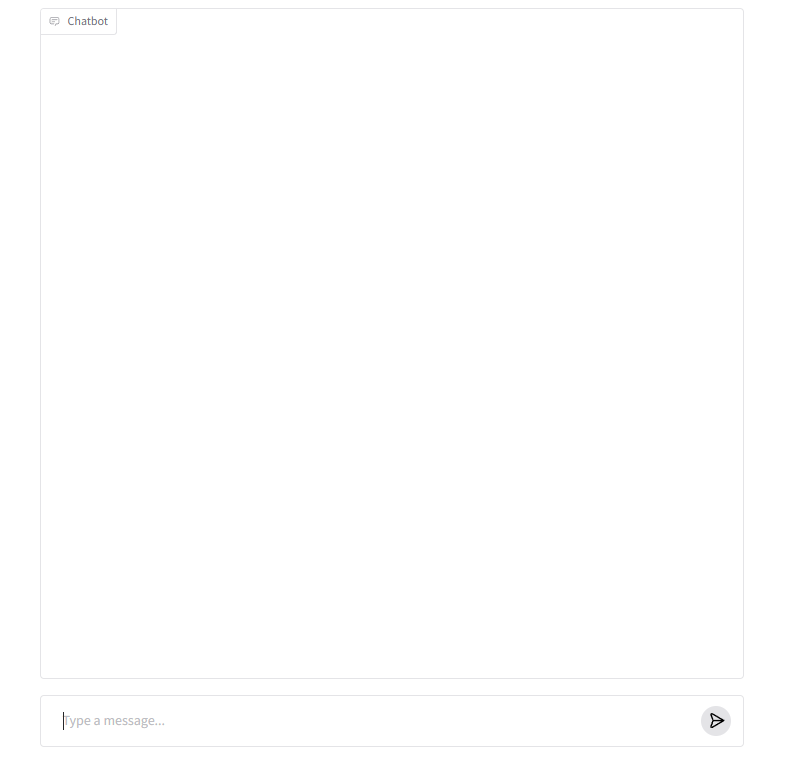
Result
I was able to run an LLM on AMD’s integrated CPU GPU. The response speed is also realistic. (It might even be faster than Gemini and similar services.)
However, I tried two models, but they didn’t work properly as follows.
(Since they don’t give exactly the same answers, I believe it’s either a model issue or a specification/hardware issue.)
microsoft/Phi-3-mini-4k-instruct(Default)- It only gives similar answers no matter what I ask (though the answers aren’t exactly identical, so it seems to be working to some extent).
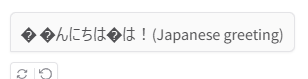
microsoft/phi-2- errors out after a few interactions or exchanges.
- Garbled Japanese Characters

コメント